



Działanie strony internetowej ma bezpośredni wpływ na stan jej zaindeksowania, który jest procesem polegającym na zebraniu zawartości strony internetowej i przedstawieniu jej w wyszukiwarce. W trakcie indeksowania wszystkie treści, grafiki oraz linki trafiają do indeksu, który jest bazą danych. Za przeprowadzanie tych czynności odpowiedzialny jest robot indeksujący, lecz zdarzają się sytuacje, że nie trafi on na naszą stronę internetową. Wówczas należy znaleźć przyczynę tej sytuacji i naprawić występujący problem. Problemy z indeksowaniem mogą dotyczyć zarówno starej jak i nowej strony internetowej. W obu przypadkach można podjąć skuteczne działa pozwalające poprawić obecną sytuację. Dlatego w tym artykule omówimy najważniejsze czynniki mające wpływ na prawidłowe indeksowanie się strony internetowej.
Blokowanie indeksowania
Jest to działanie, które zawsze powinno dotyczyć nowych stron internetowych, które nie są jeszcze ukończone. Wówczas strona w wersji roboczej nie powinna być pokazana światu zewnętrznemu, ponieważ mogłaby stanowić duplikat dla starej strony lub jej samej po przeniesieniu na docelową domenę po zakończeniu prac programistycznych. Bezpiecznymi sposobami blokującymi indeksowanie jest wykorzystanie kodu Meta robots oraz plik robots.txt.
Meta Robots
Jest to fragment kodu, który zawsze powinien znajdować się w sekcji nagłówkowej HEAD. Dyrektywa Meta robots blokujący indeksowanie ma taką strukturę:
<meta name="robots" content="parametr" />
Powyższy kod ma prostą strukturę, która może zawierać różne parametry wykazujące konkretne działanie:
- all – pozwala zaindeksować wszystko, co znajduje się na danej podstronie, podobne działanie ma zastosowanie jednocześnie index, follow,
- index – strona będzie indeksowana,
- follow – zostaną zaindeksowane linki,
- noindex – blokowanie wyświetlania strony w wyszukiwarce, powinna znaleźć zastosowanie podczas prac nad roboczą kopią nowej strony internetowej,
- nofollow – blokowanie indeksowania linków,
- none – blokowanie indeksowania strony i linków, takie samo działanie ma zastosowanie jednocześnie noindex, nofollow,
- noarchive – blokowanie zapisu strony w pamięci Cache wyszukiwarki przez co
- nosnippet – blokowanie pokazywania krótkiego opisu w wynikach wyszukiwania
- max-snippet:[liczba] – określenie maksymalnej liczby znaków opisu wyświetlanego w wynikach wyszukiwania
Plik robots.txt
Plik ten zawsze powinien znajdować się w głównym katalogu witryny. Ma on prostą strukturę, w której określone są parametry blokujące dostęp robota indeksującego do danego katalogu strony internetowej. W robots.txt powinny się znaleźć informacje o zezwoleniu dostępu do wybranych katalogów oraz ścieżce do mapy witryny:

Struktura strony internetowej i adresy URL
To jak zbudowana jest nasza strona internetowa znajduje odwzorowanie w zaindeksowanych wynikach. Dotyczy to wszystkich podstron, wpisów kategorii oraz tagów, lecz tutaj nie brakuje problemów. Wynikają one głównie ze źle przemyślanej architektury strony, w której część wpisów jest zduplikowana i nieprzypisana do żadnej kategorii lub jest i za dużo. Dochodzą do tego jeszcze nieprzyjazne adresy URL, które mogą zawierać automatyczne parametry. Dlatego struktura strony powinna być następująca:
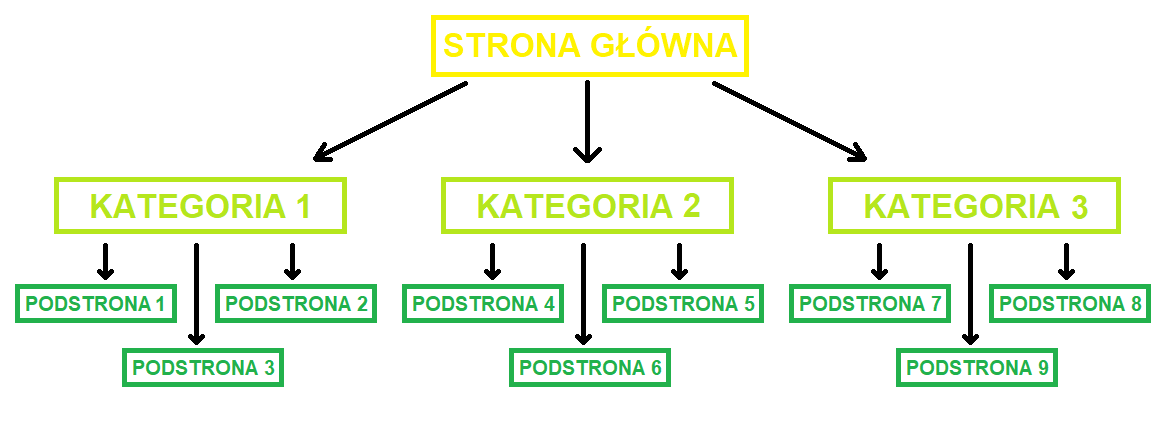
Mapa witryny i Google Search Console
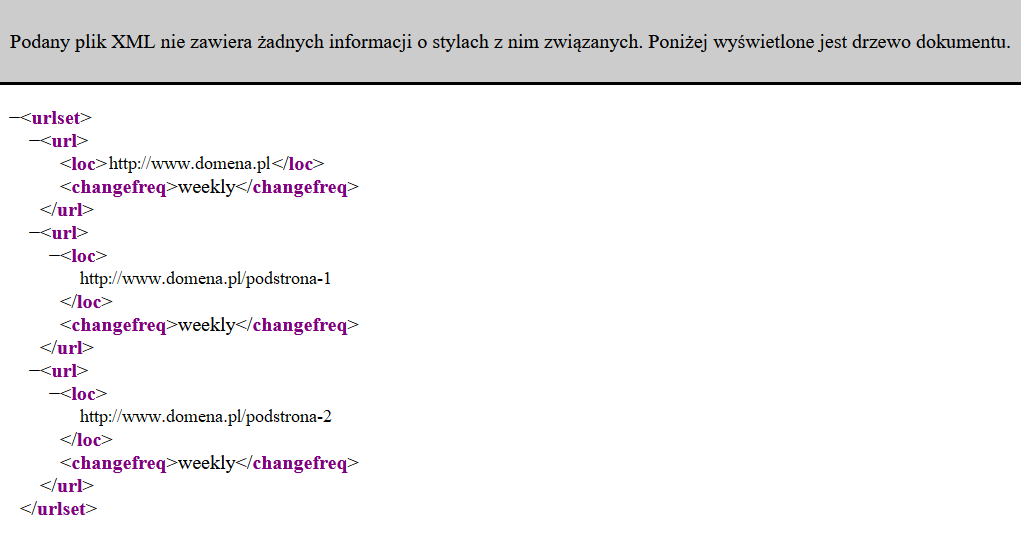
Mapa witryny jest plikiem XML, który zazwyczaj ma nazwę sitemap.xml. W przypadku stron opartych na systemach CMS mapa witryny jest generowana przy wykorzystaniu wtyczek. Jednak można ją utworzyć ręcznie samemu, lecz należy pamiętać o jej aktualizacji po publikacji nowych wpisów lub podstron. Mapa witryny jest drogowskazem dla robotów indeksujących stronę internetową, ponieważ w sitemapie zawarte powinny być wszystkie podstrony, które chcemy zaindeksować.
Przykładowa sitemapa ma taką strukturę:
Utworzenie sitemapy idzie w parze z dodaniem jej do narzędzia Google Search Console, które pełni ważną rolę w procesie indeksowania strony internetowej. To właśnie w Google Search Console jest możliwość sprawdzenia stanu indeksowania i weryfikację występujących błędów, o których zostaniemy poinformowani. Przykładem jest choćby ustawienie parametru noindex w zaindeksowanych podstronach lub pojawienie się błędów 404. GSC powiadamia również o innych błędach związanych z schema oraz wielkością elementów na konkretnych podstronach:
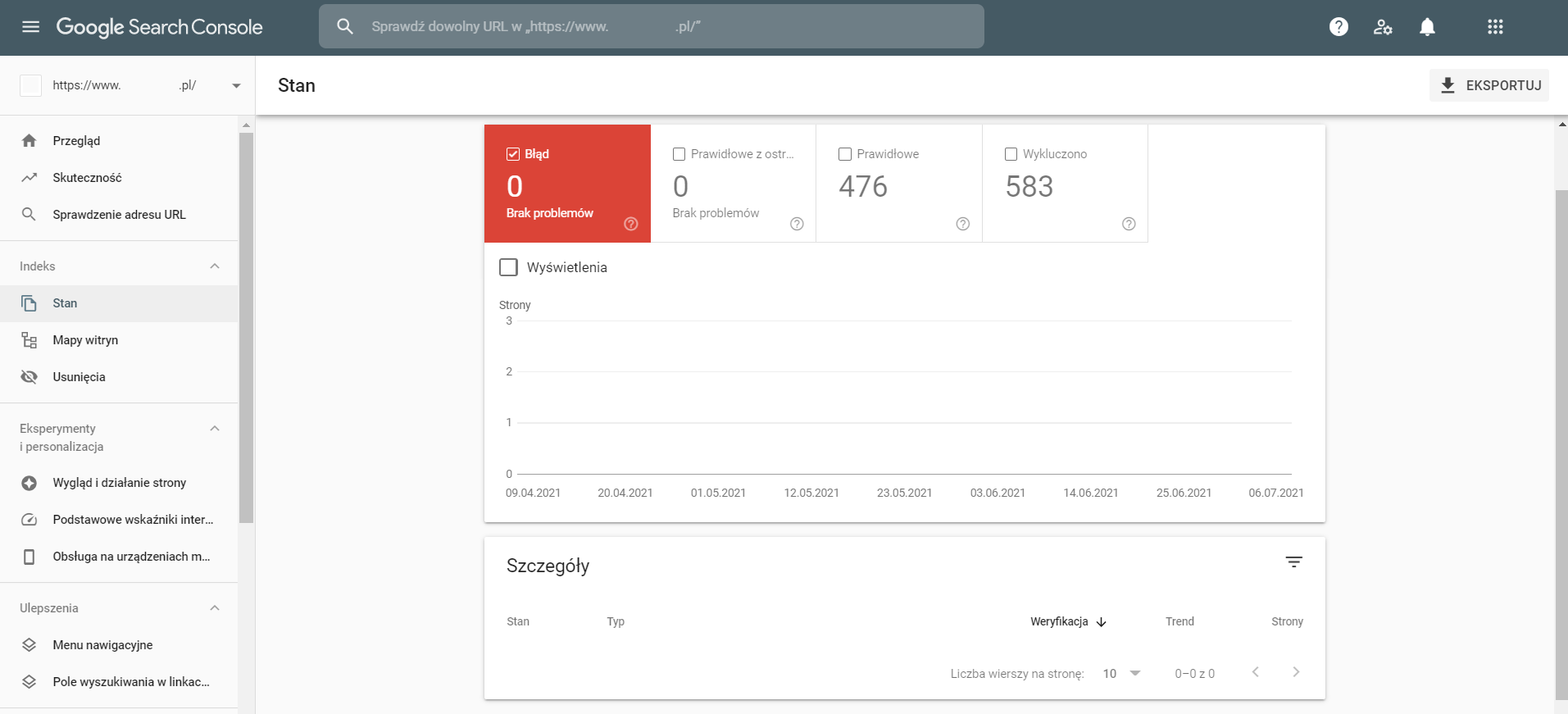
Przydatną funkcją Google Search Console jest możliwość ręcznego indeksowania podstron po zmianach, lecz efekt takiego działania jest skorelowany z szeregiem czynników wymienionych przez nas czynników i czas jego trwania jest różny. Zazwyczaj ręczne indeksowanie powinno w przeciągu paru minut wprowadzić zaktualizowaną stronę do indeksu.









